
AI大模型的未来是开源还是闭源?
IT互联网领域容易发生马太效应赢家通吃,后来者往往会试图复制当年linux或者Android的道路,通过开源的方式寻求新的发展路径和开拓新的市场潜力。
OpenAI的强势让Meta的LLAMA和阿里的qwen等都选择了开源。
然而李彦宏认为开源没戏。

以下是李彦宏的几个核心论断。
1、闭源模型在能力上会持续地领先,而不是一时地领先。
2、模型开源也不是一个众人拾柴火焰高的情况,这跟传统的软件开源一比如Linux、安卓等等很不一样。
3、闭源是有真正的商业模式的,是能够赚到钱的,能够赚到钱才能聚集算力、聚集人才。
4、闭源在成本上反而是有优势的,只要是同等能力,闭源模型的推理成本一定是更低的,响应速度一定是更快的。
5、无论中美,当前最强的基础模型都是闭源的。通过基础模型降维做出来的模型也是更好的,这使得闭源在成本、效率上更有优势。
6、对于AI创业者来说,核心竞争力本就不应该是模型本身,这太耗资源了,而且需要非常长时间的坚持才能跑出来。
7、既做模型又做应用的“双轮驱动”,对创业公司不是好模式。创业公司的精力和资源都很有限,更应该专注。既做模型又做应用,势必会分散精力。
这很有趣。
说实话这很符合大众对李彦宏的刻板印象。李彦宏的“中文互联网发展减速器”的人设进一步加强了。
我一直不喜欢百度,但是今天也不禁要想:去年以来无数号称想拿着开源的LLAMA2 做一番事业的人在一年时间里陆续哑了火。
AI大模型和之前任何一次技术突破都有很大不同,大模型基座的开源意义到底有多大?
当然对于研发人员来说开源总是好的,大家能够更开放的交流和进行相关技术的研究。和无数开源项目类似的,开放源代码大型语言的亮点:
开源大型语言模型 (LLM) 的公开研究十分宝贵,因为它旨在将一项强大且具有影响力的技术民主化。
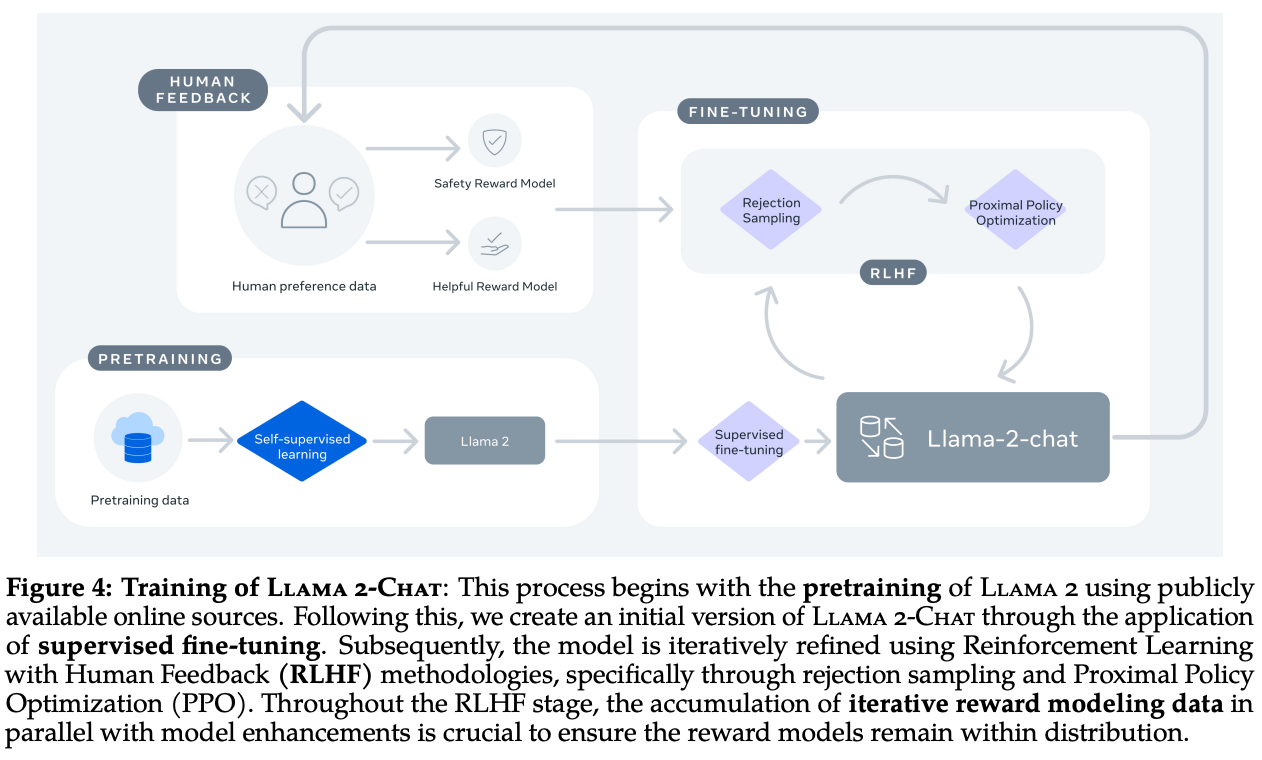
然而和其他技术不同的是,开源LLM的基座之后仍需要应用开源模型的一方投入巨量算力进行训练。没有训练的基座可以说是毫无实用价值的。而且,训练不好的基座同样意义有限。尽管开源 LLM 现在被广泛使用并广泛研究,但该研究领域最初遇到了难以克服的困难。确切地说,早期的开源 LLM 表现不佳,并受到严厉批评。无数中小团队在各种反对声音之下毅然决然的投入了数百万甚至上千万美元的费用实用开源LLM基座进行训练最终一无所获。
鉴于预先训练语言模型的成本如此之高,在这些高性能基本模型被创建和发布之后,许多人可以在边际成本很低的情况下使用这些模型进行研究。是的,仅限于研究……
圈内很多人说要投入10亿人民币以上的资金进行算力采购和训练就会有好结果。但是这里无法回避两个问题:
1,谁有好结果了?
2,我要是有数十亿甚至上百亿资金,我是不是还要选择开源模型去进行训练?
本文参考了《The History of Open-Source LLMs: Better Base Models》by:CAMERON R. WOLFE, PH.D.
https://cameronrwolfe.substack.com/p/the-history-of-open-source-llms-better